

Search engines catalog pages found on the internet by using special programs called spiders that “crawl” websites and logically group information by the content they find. This is a process called indexing and can be likened to a library card catalog where the relevant information is stored for retrieval.
In the case of the search engines, this index is a complex repository allowing multiple ways to access the information via a search query. The information that the crawler sees in a webpage is pulled from both the content on the page and the “meta data” located within the page code. This meta data includes the page title, page description, and many more content attributes. We can optimize these areas of meta data to improve the search relevance for important or popular search term.
Just like with a traditional webpage, there is a function within Adobe Acrobat to add relevant information that can improve the “searchability” of a PDF document. The search engines look for the same attributes in a PDF file that they look for in a webpage. These attributes include:
- Document or file name
- Document title
- Authors/Owners (if appropriate)
- Document subject (similar to meta description)
- Relevant keywords
This important document information is located in the document properties under the “description” tab. The example below, taken from the Adobe Acrobat XI quick-start guide on the Adobe website, shows the fields that contain this information:
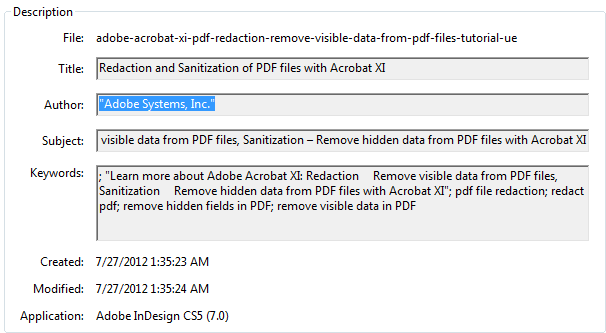
Document/File Name:
The document or file name is often left up to the discretion of the author. The format of the file name can be as varied and as individual and the author’s personal naming system and can include a recognizable nomenclature or naming structure.
This document has some clearly visible traits in the file name “adobe-acrobat-xi-pdf-redaction-remove-visible-data-from-pdf-files-tutorial.pdf”. The image below shows how the file name shows up in the search engine result. The author did a nice job of clarifying the Adobe product name in the title, making it more relevant for the searcher.

Document Title:
The image above shows the Google search result for this document. The main link in blue has been pulled directly from the document title. This provides PDF authors a significant opportunity to provide a very relevant and descriptive search title. The goal of creating a compelling title is to leverage the search engine algorithm, which looks to return the most relevant result for a given search. In addition, the use of targeted keywords in the title is essential just as it is with a webpage. The keywords in this title include the “brand” terms PDF files and Acrobat XI along with the “non-brand” terms redaction and sanitization.
Document Subject:
The document subject in a PDF document plays the same role as the Meta description in a webpage. The part of the search engine result that describes the content of the result is called the “snippet” and is usually right below the main link. The search engines will first try to pull the content for the snippet from the first paragraph or 250 words of the target page; if that is not the most relevant description, the search engine will use the meta description or the document description in the case of a PDF document. The example above shows that the first part of the snippet was pulled from keyword occurrences at the start of the document.
Keywords:
The keywords field in the document properties of a PDF document provides a location for a list of important keywords found within the document. This helps the search engines by providing additional data for scoring the pages for relevant keywords not located in the title or subject fields. Some rules of thumb include:
– Try to always use the same field for similar information. For example, don’t add an important term to the Subject option for some documents and to the Keywords option for others.
– Use a single, consistent term for the same information. For example, don’t use biology for some documents and life sciences for others.
– Another option is to use the Subject or Keywords option, either alone or together, to categorize documents by type. For example, you might use status report as a Subject entry and monthly or weekly as a Keywords entry for a single document.
Document Author:
The document author is an important field for grouping documents by the team or group that was responsible for their creation. An example would include a hiring policy document, which would have the “Human Resources” department in the Author field. This could also be used to demonstrate the core competency of a particular thought leader within the organization.
Summary:
The importance of natural search is driving the need to provide the best possible results for the searcher. This effort includes providing better search results, better user experience, and improved asset management. In the end, this expanded use of meta data simply tells more about the many documents located on websites and making these PDFs easier to find and manage through search.

Hi Bloggers! Submit your Guest Post on these Blogs for free for all Niche
ReplyDeleteGuestBlogger.in Guest Blog for bloggers
AskMeBlogger.com Online Marketing and SEO BLog
VistaBlogger.com Internet marketing blog
BigRankBlog.com All Niche BLog
WebHostingBlogger.net Web Hosting BLog
WebThemesBlog.com Website Themes BLog
SaveMoneySale.com Online Shopping Discount Coupon BLog
HealthFitnessAndYoga.com Health Fitness and Yoga BLog
ShinePage.com Post Free Classified Ads
really a vry nice blog i really appreciate all your efforts ,thank you so mch for sharing this valuable information with all of us
ReplyDeleteOn the off chance that you are hoping to profit our administrations then it's an opportune time. You simply #need to visit our site and look at the colossal rundown of Packers And Movers Bangalore You need to guarantee that you pick just those people who are better ready to coordinate your prerequisites.
http://packers-movers-bangalore.in/
This is a wonderful article, Given so much info in it, These type of articles keeps the users interest in the website, and keep on sharing more ... good luck. Grass fed ghee
ReplyDelete